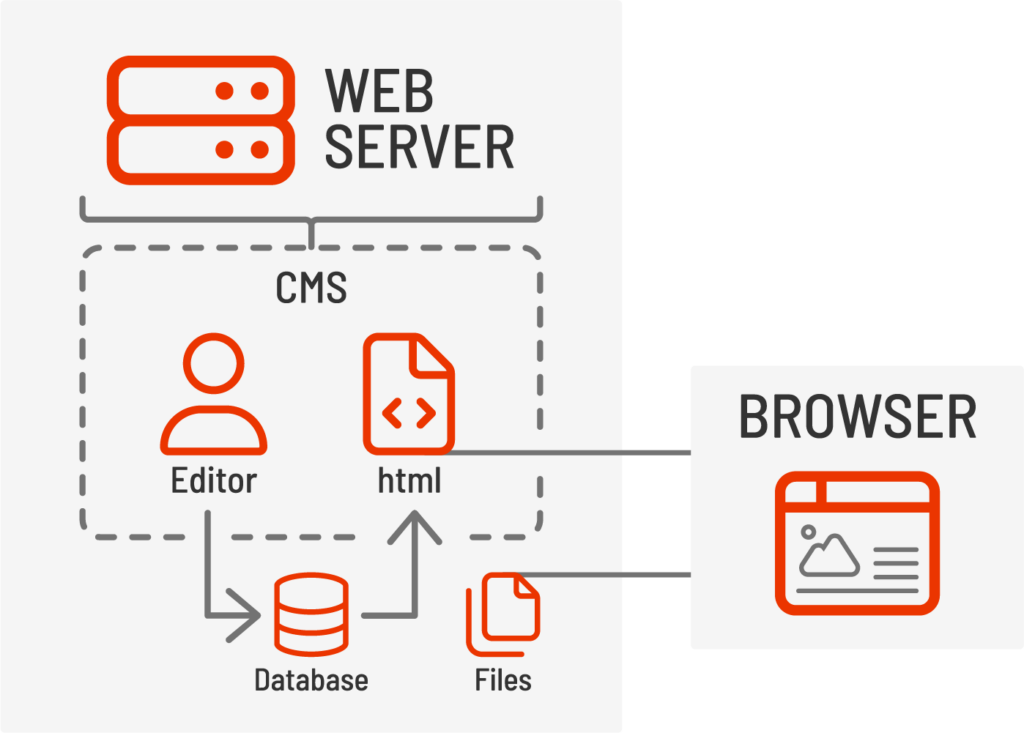
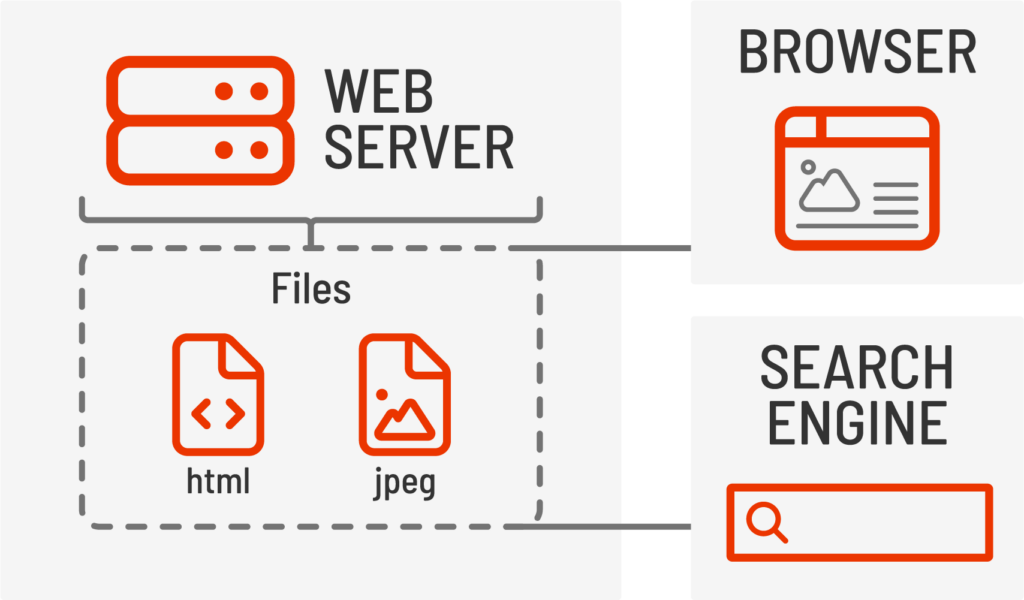
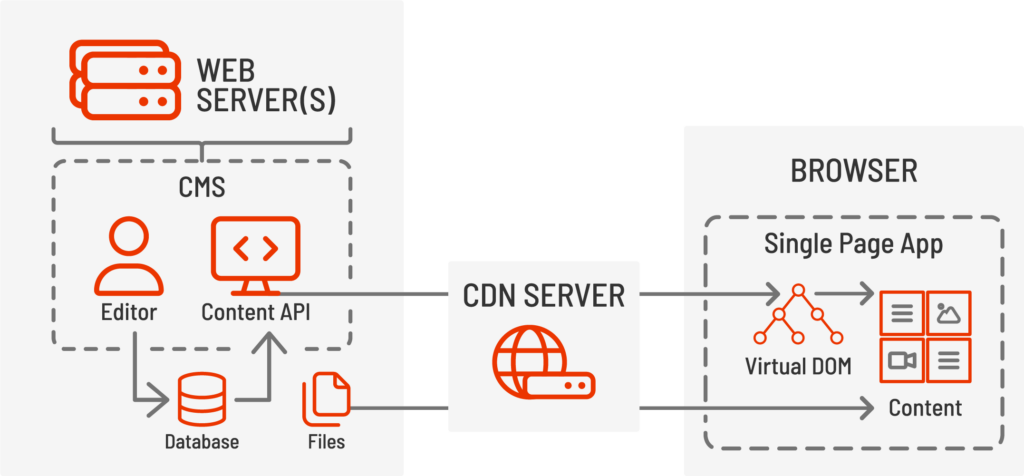
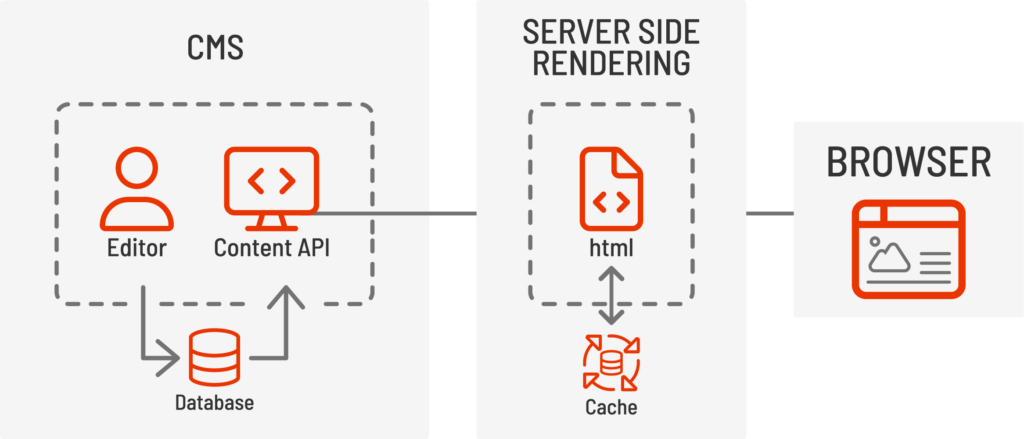
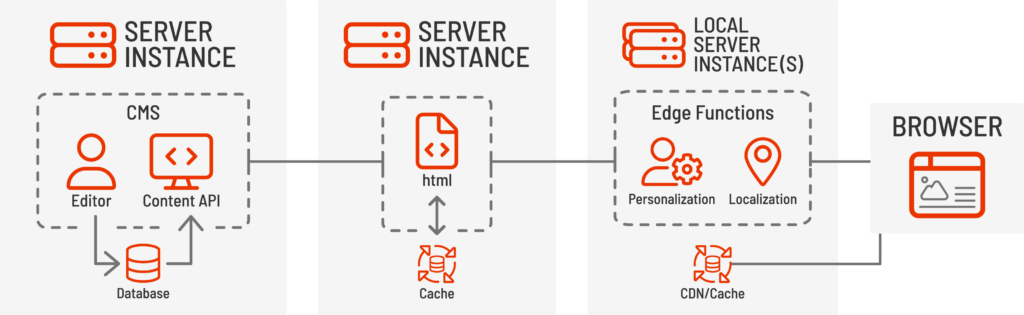
Les systèmes de gestion de contenu headless, tels que les sites Jamstack ou Strapi, ainsi que les plateformes d'expérience numérique traditionnelles comme Sitecore ou Adobe Experience Manager avec extensions headless, conservent généralement les fonctionnalités d'authentification et d'édition ainsi que le stockage de contenu, tandis qu'une interface distincte est utilisée pour afficher le contenu final aux utilisateurs finaux. Les CMS headless utilisent généralement une API REST ou GraphQL pour fournir le contenu et les données à l'interface afin d'assembler et de restituer la page web finale et l'expérience utilisateur directement dans le navigateur.
Différentes couches de présentation peuvent être utilisées pour combiner, restituer et répondre aux comportements des utilisateurs sans complexifier le CMS lui-même. Les CMS headless permettent également la mise en cache de contenu, l'évolutivité et des cycles de déploiement plus courts pour les microservices, contrairement aux versions plus longues des grands projets monolithiques.