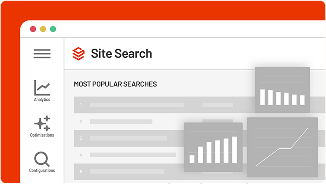
La solution SearchStax Site Search offre aux spécialistes du marketing l'agilité dont ils ont besoin pour optimiser les résultats du site Web.
Présentation du produit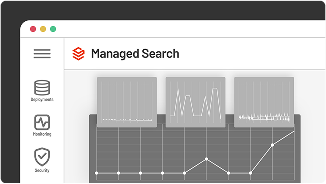
SearchStax Managed Search décharge la gestion de Solr, offrant aux équipes informatiques une agilité opérationnelle accrue.
Présentation du produit